







Reinforcement Machine Learning (RL) is a type of machine learning where an agent learns to make decisions by interacting with an environment. The agent performs actions, receives rewards (or penalties), and adjusts its strategy to maximize cumulative rewards over time. Unlike supervised learning, RL does not rely on labeled data but instead learns through trial and error.
Core Components:
- Agent: The learner or decision-maker (e.g., a robot, game AI).
- Environment: The world in which the agent operates (e.g., a chessboard, autonomous vehicle simulator).
- State (s): The current situation of the agent.
- Action (a): A decision made by the agent.
- Reward (r): Feedback from the environment (e.g., +1 for winning, -1 for losing).
- Policy (π): A strategy mapping states to actions (e.g., “if in state X, choose action Y”).
- Value Function: Estimates the expected long-term reward of a state or action.
- Q-Value: The expected reward for taking an action in a state and following the policy thereafter.
How It Works:
1.) Interaction Loop:
- The agent observes the current state.
- Selects an action based on its policy.
- Receives a reward and transitions to a new state.
- Updates its policy to favor actions that maximize future rewards.
2.) Exploration vs. Exploitation:
- Exploration: Trying new actions to discover their effects.
- Exploitation: Using known high-reward actions.
- Balanced via strategies like ε-greedy (e.g., 90% exploit, 10% explore).
3.) Learning Mechanisms:
- Model-Based RL: Uses a pre-defined or learned model of the environment to plan (e.g., chess AI predicting opponent moves).
- Model-Free RL: Learns directly from experience without a model (e.g., Q-learning).
Key Algorithms:
- Q-Learning: Learns a Q-value table to choose optimal actions.
- Deep Q-Networks (DQN): Uses neural networks to approximate Q-values for complex environments (e.g., video games).
- Policy Gradient Methods: Directly optimizes the policy (e.g., REINFORCE, Proximal Policy Optimization).
- Actor-Critic: Combines value-based and policy-based approaches for stable learning.
Applications:
- Gaming: AlphaGo, Dota 2 AI.
- Robotics: Teaching robots to walk or manipulate objects.
- Autonomous Systems: Self-driving cars, drone navigation.
- Healthcare: Personalized treatment plans.
- Finance: Portfolio optimization, algorithmic trading.
- Recommendation Systems: Adaptive content suggestions (e.g., Netflix, Spotify).
Challenges:
- Sparse/Delayed Rewards: Critical feedback may occur infrequently (e.g., winning a game after hours of play).
- High-Dimensional Spaces: Complex states/actions (e.g., raw pixel input in games).
- Sample Inefficiency: Requires vast interactions to learn (mitigated via simulations).
- Safety: Avoiding harmful actions during exploration (e.g., autonomous vehicles).
- Reward Design: Poorly designed rewards can lead to unintended behavior (“reward hacking”).
Real-World Example:
AlphaGo: Google’s AI mastered Go by playing millions of games against itself, learning strategies that surpassed human champions.
Future Directions:
- Meta-Learning: Agents that learn to learn across tasks.
- Multi-Agent RL: Collaborative/competitive environments (e.g., traffic control).
- Ethical AI: Ensuring fairness and safety in RL systems.
Comparison with Others:
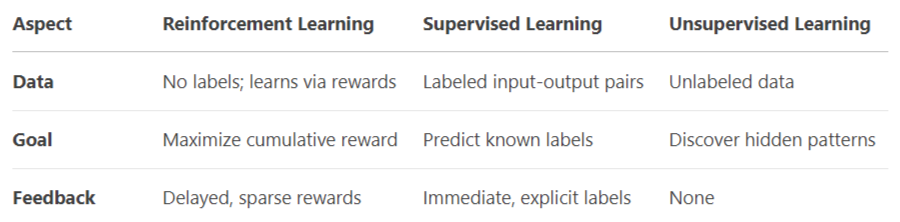
Reinforcement Machine Learning: (Summary)
Reinforcement Machine Learning (RL) is a dynamic AI paradigm where an agent learns to make decisions by interacting with an environment to maximize cumulative rewards. Unlike supervised learning (labeled data) or unsupervised learning (unlabeled patterns), RL focuses on trial and error exploration. The agent performs actions, observes outcomes, and receives feedback as rewards or penalties, refining its strategy over time.
Central to RL are states (environmental conditions), actions (agent’s choices), rewards (performance feedback), and a policy (strategy mapping states to actions). Algorithms like Q-learning and Deep Q-Networks (DQN) use value-based methods to optimize decisions, while policy gradient techniques directly adjust action probabilities. Exploration vs. exploitation balancing new actions with proven strategies is a core challenge.
RL excels in complex, dynamic domains: training robots for precise movements, developing game playing AI (e.g., AlphaGo), optimizing autonomous vehicle navigation, and personalizing recommendation systems. It’s also used in resource management, finance, and healthcare for adaptive decision making.
Assuring safe exploration in practical applications, managing sparse/delayed rewards, and high processing costs are among the difficulties. Risks during training are frequently reduced in simulated settings. Although there are challenges, RL’s capacity to learn complex tasks on its own without the use of explicit datasets makes it a key component of adaptive AI, propelling advancements in robotics, automation, and intelligent systems. Through interaction based learning, RL helps close the gap between theoretical models and practical problem solving.
Read Also: What Is Semi-supervised Machine Learning?