







Semi-Supervised Machine Learning is a hybrid approach that combines elements of supervised and unsupervised learning to train models using both labeled and unlabeled data. It bridges the gap when labeled data is scarce (expensive or time-consuming to obtain) but unlabeled data is abundant. The goal is to leverage the unlabeled data to improve model accuracy and generalization beyond what purely supervised methods could achieve with limited labeled examples.
How It Works:
1.) Input Data:
- Labeled Data: A small subset of data with known outputs (e.g., 100 images labeled “cat” or “dog”).
- Unlabeled Data: A larger pool of data without labels (e.g., 10,000 unclassified images).
2.) Learning Process:
- The model first learns patterns from the labeled data.
- It then uses the structure or distribution of the unlabeled data to refine its understanding.
-
Common techniques include:
-
Self-Training: The model labels unlabeled data with high confidence and retrains on this pseudo-labeled data.
-
Co-Training: Multiple models train on different feature subsets and cross-label data for each other.
-
Generative Models: Learn the data distribution (e.g., GANs, variational autoencoders) to infer latent patterns.
-
Key Algorithms:
- Self-Training (e.g., semi-supervised SVM).
- Label Propagation: Spread labels to unlabeled points based on similarity.
- Graph-Based Methods: Use graph structures to model relationships between labeled and unlabeled data.
- Semi-Supervised Deep Learning (e.g., MixMatch, FixMatch).
Applications:
- Image and Speech Recognition: Labeling audio/video data is labor-intensive.
- Medical Diagnosis: Limited expert-labeled scans but abundant unlabeled patient data.
- Text Classification: Classifying documents with few labeled examples.
- Fraud Detection: Identifying rare fraudulent patterns in mostly unlabeled transactions.
Advantages:
- Cost-Effective: Reduces reliance on expensive labeled data.
- Improved Performance: Leverages unlabeled data to capture broader data patterns.
- Scalability: Useful in domains like IoT or social media, where unlabeled data is plentiful.
Challenges:
- Quality of Unlabeled Data: Noisy or irrelevant unlabeled data can degrade performance.
- Assumption Dependency: Relies on assumptions like the cluster assumption (similar data points share labels) or manifold assumption (data lies on a low-dimensional manifold).
- Complexity: Harder to implement than purely supervised/unsupervised methods.
Example:
💡Imagine training a model to classify emails as “spam” or “not spam”:
- Labeled Data: 100 emails manually tagged.
- Unlabeled Data: 10,000 untagged emails.
- The model uses the labeled data to learn basic patterns, then infers labels for the unlabeled emails based on similarities (e.g., shared keywords). It retrains iteratively to improve accuracy.
When to Use Semi-Supervised Learning?
- Labeled data is limited, but unlabeled data is abundant.
- The cost of labeling is prohibitive.
- The data has inherent structure (e.g., clusters) that unlabeled examples can help uncover.
Comparison with Others:
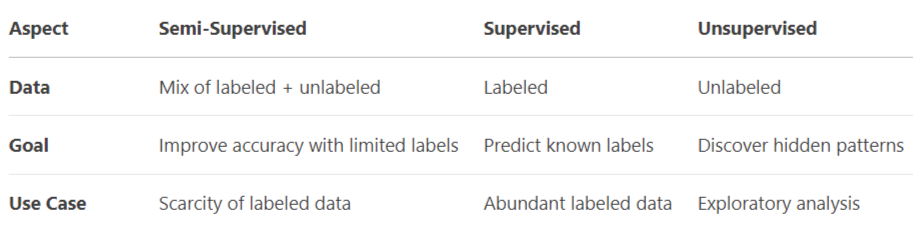

Semi-supervised Machine Learning: (Summary)
Semi-supervised machine learning bridges the gap between supervised and unsupervised approaches by leveraging both labeled and unlabeled data. While supervised learning relies entirely on labeled datasets (with explicit outputs) and unsupervised learning uses only unlabeled data, semi-supervised methods combine the two to improve model performance while reducing dependency on costly labeled data. This hybrid approach is particularly valuable in real-world scenarios where acquiring labeled data is time-consuming, expensive, or impractical, but unlabeled data is abundant.
Key techniques include self-training, where a model iteratively labels high-confidence unlabeled data and retrains itself, and co-training, which uses multiple models to label data collaboratively. Other methods include pseudo-labeling and transudative learning, which infer labels for unlabeled data based on patterns in labeled examples. These strategies enhance generalization and accuracy, especially when labeled samples are limited.
Applications span domains like natural language processing (NLP) (e.g., text classification), computer vision (e.g., medical imaging with sparse annotations), and speech recognition. For instance, semi-supervised models can improve fraud detection systems by learning from a small set of confirmed fraud cases and vast unlabeled transaction data.
Challenges include preventing error propagation from poorly labeled data and guaranteeing the validity of pseudo-labels. Despite these challenges, semi-supervised learning is essential for sectors looking for scalable AI solutions since it provides a practical compromise between performance and efficiency. Through the strategic use of existing data, it reveals insights that may be overlooked by strictly supervised or unsupervised approaches.
Read Also: What Is Unsupervised Machine Learning?